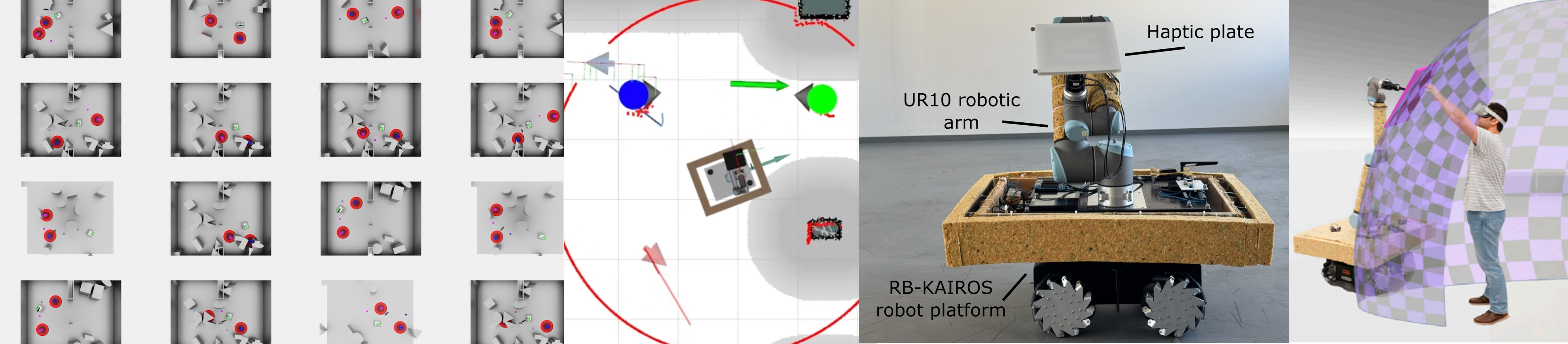
The Goal
The primary objective was to solve a critical safety and latency challenge in Virtual Reality (VR) haptics. Specifically, I needed to control CoboDeck, a massive 120kg omnidirectional mobile robot capable of speeds up to 3.0 m/s. This robot acts as a “Mobile Encountered-Type Haptic Display” (mETHD), meaning it must autonomously drive to specific locations to provide physical touch feedback (like a wall or furniture) exactly when a user reaches out in VR.
The core problem was that existing rule-based navigation systems were too slow and reactive, often leading to safety stops that broke immersion. My goal was to develop a system that could:
- Ensure Safety: Navigate around “blind” users wearing Head-Mounted Displays (HMDs) without collision.
- Minimize Latency: Proactively position the robot before the user needs it.
- Scale to Multi-User: Handle complex scenarios with multiple moving users in the same physical space.
The How
To achieve proactive and safe behaviors, I moved away from traditional path planning and engineered an end-to-end Deep Reinforcement Learning (DRL) framework.
- Deep Reinforcement Learning (DRL): I utilized the Proximal Policy Optimization (PPO) algorithm to train a neural network policy that outputs continuous velocity commands directly to the robot.
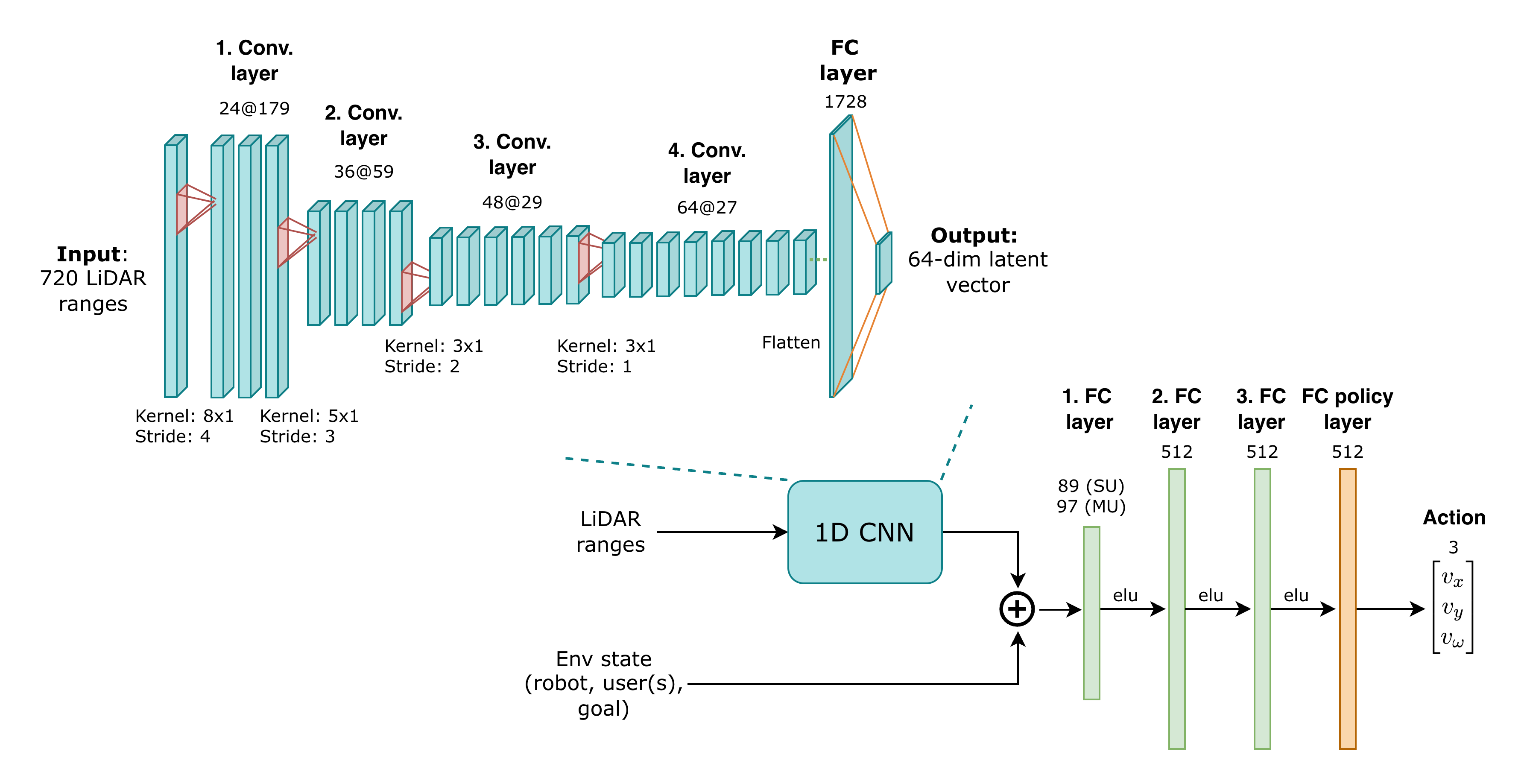
- Sensor Fusion & Perception: To handle obstacle avoidance, I processed raw 720-ray 2D LiDAR data using a custom 1D Convolutional Neural Network (CNN). This allowed the agent to extract spatial features (like gaps and edges) directly from sensor data, which was fused with high-precision user tracking data.
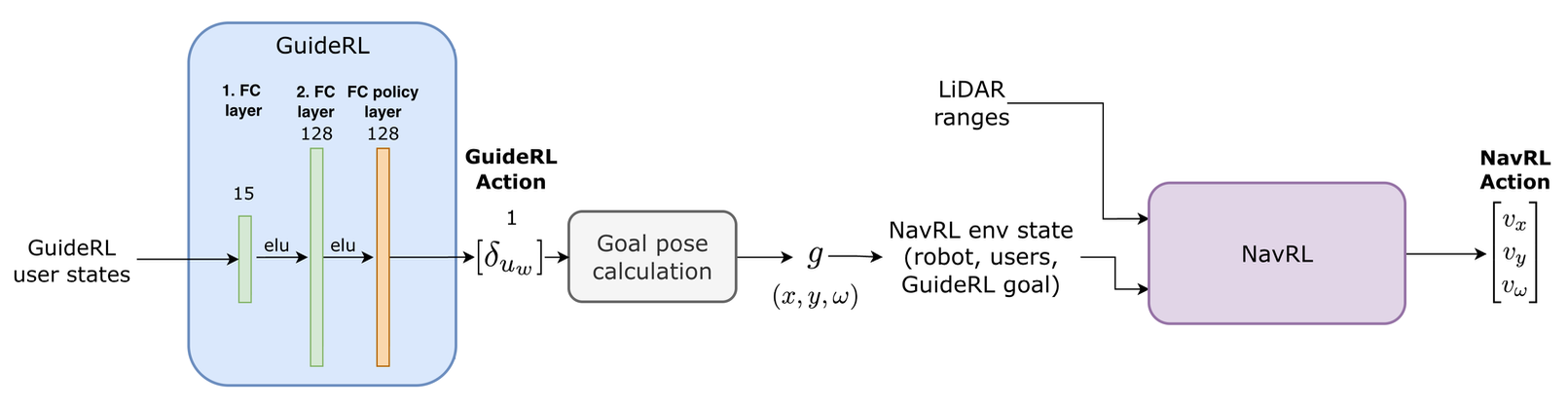
- Hierarchical Policy Decomposition: For the complex multi-user scenario, I split the problem into two specialized networks to ensure convergence:
- GuideRL: A high-level strategic policy that predicts which user is most likely to need haptic feedback next.
- NavRL: A low-level navigation policy that executes the movement while avoiding dynamic obstacles (users).
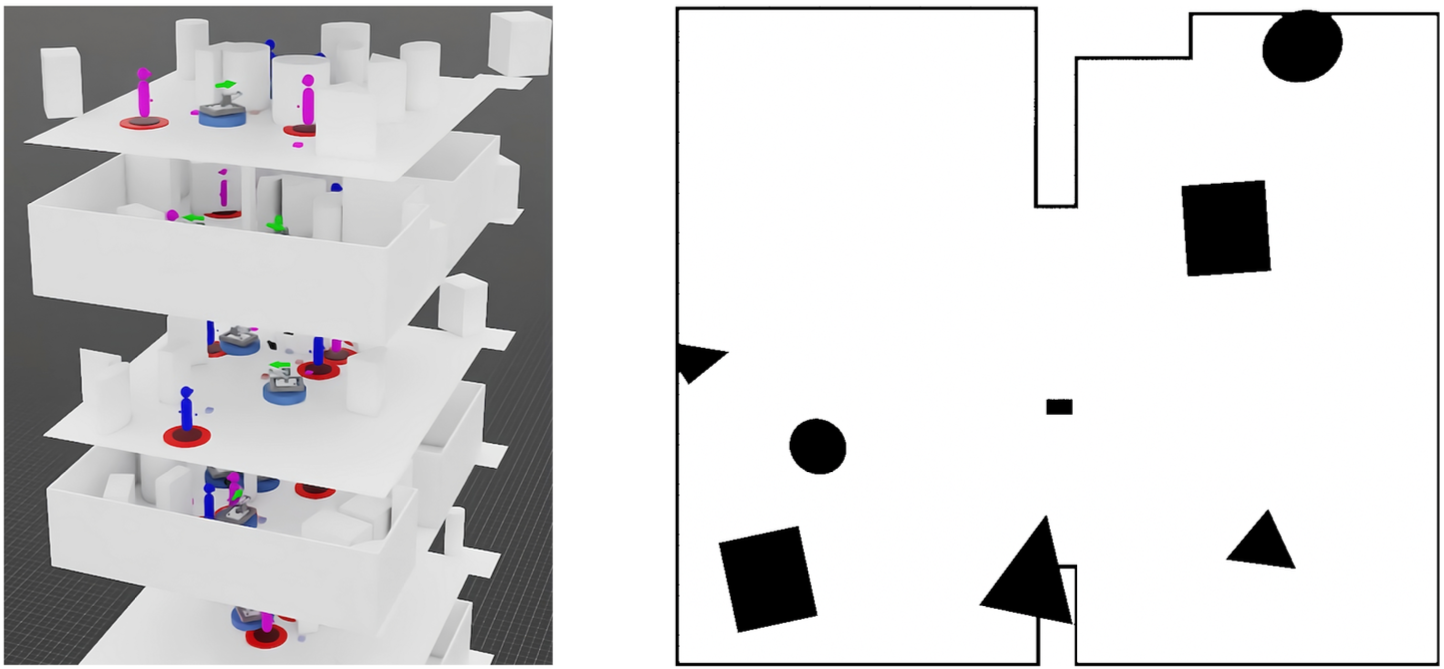
- Simulation & Training: I built a custom training environment using NVIDIA Isaac Sim and Isaac Lab. To prevent overfitting, I trained the agent in procedurally generated environments with randomized obstacles and simulated sensor noise (domain randomization) to ensure the policy would transfer to real-world conditions.
- Evaluation: I benchmarked the DRL policies in simulation against a traditional rule-based baseline in both single-user and multi-user scenarios, measuring safety stops, positioning latency, and overall responsiveness.
The Results
The DRL approach demonstrated a significant leap in performance compared to traditional static and heuristic baselines, validated through extensive simulation testing.
- Drastic Safety Improvement: In multi-user scenarios, the DRL policy reduced safety-critical interventions (emergency stops) by over 88% compared to the baseline. In single-user tests, safety stops were reduced by approximately 98%.
- Superior Responsiveness: The system improved haptic positioning times by up to 6x. In multi-user scenarios, the DRL agent achieved a median positioning time of 1.07 seconds versus 6.04 seconds for the baseline.
- High-Precision Prediction: The strategic “GuideRL” policy achieved 99% accuracy in predicting the correct target user, allowing the robot to react proactively rather than reactively.
- Proactive Behavior: The agent learned to maintain a “ready” state, actively repositioning itself to minimize distance to potential interaction points, trading off energy efficiency for maximum readiness and safety.